一、前言
关于多目标跟踪(MOT)这方面的知识,对于我来说是一个新的知识点。此前并没有接触过此方面的内容,所以对于 SiamMOT 本篇论文的论述也是会比较表面一点,我也仅仅是略懂其中的皮毛。在后续的工作中,也希望能将本篇文论作为一个切入点,去接触更多的有关多目标跟踪的内容。
二、Multiple Object Tracking
单目标跟踪(SOT)与多目标跟踪(MOT)
首先,之前了解过单目标跟踪(SOT)就是在视频的初始帧画面上框出单个目标,预测后续帧中该目标的大小与位置。典型算法有Mean shift(用卡尔曼滤波、粒子滤波进行状态预测)、TLD(基于在线学习的跟踪)、KCF(基于相关性滤波)等。
多目标跟踪(MOT)不像像单目标追踪一样先在初始帧上框出单个目标,而是追踪多个目标的大小和位置,且每一帧中目标的数量和位置都可能变化。此外,多目标的追踪中还存在下列问题:
- 处理新目标的出现和老目标的消失;
- 跟踪目标的运动预测和相似度判别,即上一帧与下一帧目标的匹配;
- 跟踪目标之间的重叠和遮挡处理;
- 跟踪目标丢失一段时间后再重新出现的再识别。
首先 MOT 是检测目标实例,然后将它们在时间上关联以形成轨迹的问题。这里的关联则是进行互相关运算。
互相关运算简单来说就是计算机根据帧中的某个目标,在下一帧中需要找到相同的目标,而在识别这个中间过程就需要去度量其相似性。那么互相关运算就是去度量两者的相似性。在离散的图像空间中,数学定义式:
\[(f * h)[i, j] = \sum^{k}_{u=-k}\sum^{k}_{v=-k}h[u, v] f[i+u, j+v]\]其中 $h$ 和 $f$ 分别为核和图像,代表着要搜索的目标模板和存在要搜索的目标的图像。
在线跟踪(Online Tracking)和离线跟踪(Offline Tracking)
作者文中提出,目前具有较强竞争力的跟踪器都是在线跟踪器(论文:“Tracking without bells and whistles”&“Tracking objects as points”)
浅显认为:在线跟踪要求处理每一帧时,决定当前帧的跟踪结果时只能利用当前帧和之前的帧中的信息,也不能根据当前帧的信息来修改之前帧的跟踪结果。
离线跟踪则允许利用之后的帧的信息从而获得全局最优解。这也是在早期MOT作品中,会构建一个大型离线图,这可以重新识别跨度越大时间间隔实例。离线追踪的设定也不太适合实际应用场景,但是以一种“batch”的形式进行的离线跟踪(每次得到若干帧,在这些帧中求全局最优)也是可行的,只是会导致一点延迟。因此不适用于实时跟踪。
 图源:博客网图(上:在线跟踪;下:离线跟踪)
图源:博客网图(上:在线跟踪;下:离线跟踪)
Simple and Online Realtime Tracking (SORT)
SORT 算法的核心是 匈牙利匹配算法 和 卡尔曼滤波算法 。是以 Tracking-by-Detection 检测跟踪范式解决MOT,其中检测作为关键组件,传播目标状态到未来帧中,将当前检测与现有目标相关联,并管理跟踪目标的生命周期。
通过了解,SORT 算法输入是已有 bounding box 的数据,并且SORT是用于实时在线跟踪,能够拿到上一帧和当前帧的数据。SORT 算法输出则是对于每一个目标都有自己的ID,作为该目标轨迹的唯一标识。
- 以(Intersection-over-Union)IoU 表示两个物体之间的距离,作为前后帧间目标关系度量指标;
- 根据 IoU 构建关联矩阵(匈牙利算法核心)从而关联检测框到目标;
- 对于目标的观测值,采用目标检测算法(Faster-RCNN);
- 状态估计,利用卡尔曼滤波器预测当前位置;
当然,有关 SORT 多目标跟踪算法还需进一步深入了解。
三、SiamMOT Introduction
SiamMOT 是建立在 Simple and Online Realtime Tracking (SORT) 基础上,去探索 Online MOT 中运动建模的重要性。因为作者认为:更好的运动模型是提高局部连接精度的关键。
SiamMOT 是将基于区域检测网络(Faster-RCNN)与两个运动模型(隐式运动模型(IMM)和显式运动模型(EMM))相结合。并且与CenterTrack基于点的特征进行隐式的目标运动预测不是,SiamMOT基于区域的特征并开发显式模板匹配来估计实例运动,在快速运动场景下具有更强的鲁棒性。
相关工作:
- Siamese trackers 学习一个匹配函数,用于搜索在更大的上下文区域内检测到的实例目标
- Tracking-by-Detection in MOT
- 在每一帧中检测实例目标
- 根据它们的诗句连贯性和时空一致性跨时间关联
- Online MOT 侧重与准确的局部关联
- Motion modelling in SORT 探索运动建模重要性
四、SiamMOT: Siamese Multi-Object Tracking
- 建立在 Faster-RCNN 目标检测器之上,并添加了一个基于区域的 Siamese Tracker 来模拟实例级运动
- Faster-RCNN 由 Region Proposal NetWork (RPN) 和基于区域的检测网络组成
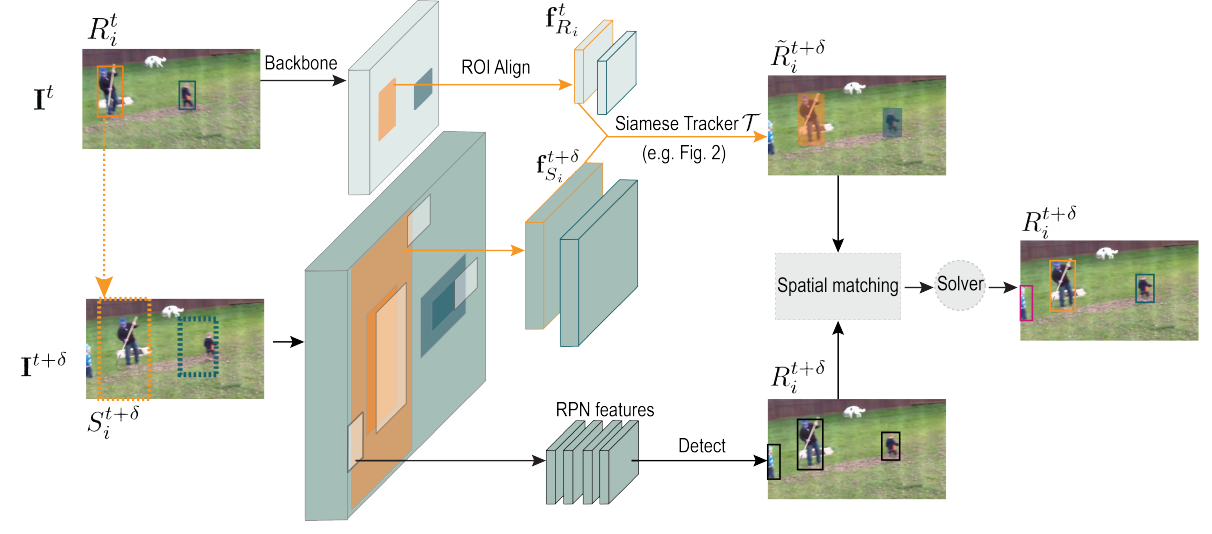
- 将两帧 $I^t$ 、 $I^{t+\delta}$ 以及一组检测到 $t$ 时刻的实例 $\mathbf{R}^t = {R^t_1, … R^t_i, … }$ 作为输入
- 检测网络输出一组检测到的实例 $R^{t+\delta}$ ,而追踪器将 $R^t$ 传播到时间 $t+\delta$ 以生成 $\tilde{R}^{t+\delta}$
- 和 SORT 一样,SiamMOT 包含一个运动模型,可以跟踪每一个 $t$ 到 $t+\delta$ 时间中通过将时间 $t$ 的 bounding box $R^t_i$ 传播到 $t+\delta$ 中 $\tilde{R}^{t+\delta}_i$ 的被检测到的实例。
- 空间匹配过程中,将跟踪器输出的 $\tilde{R}^{t+\delta}_i$ 与 $t+\delta$ 时刻的检测 $R^{t+\delta}_i$ 相关联,从而检测到的实例从 $t$ 连接到 $t+\delta$
Motion modelling with Siamese tracker
首先,给定一个在 $t$ 时刻被检测到的实例 $i$ ,Siamese tracker 会根据在 $t$ 帧中的位置在 $I^{t+\delta}$ 帧的一个局部窗口范围内搜索对应的实例。
\[(v^{t+\delta}_i, \tilde{R}^{t+\delta}_i) = \mathcal{T}(\mathbf{f}^t_{R_i}, \mathbf{f}^{t+\delta}_{S_i}; \Theta)\]- 其中 $\mathcal{T}$ 表示参数为 $\Theta$ 的 Siamese 跟踪器,而 $\mathbf{f}^t_{R_i}$ 是在 $I^t$ 帧上根据检测框 $R^t_i$ 提取出的特征图,而 $\mathbf{f}^{t+\delta}_{S_i}$ 则是在 $I^{t+\delta}$ 帧上的搜索区域 $S^{t+\delta}_i$ 提取出的特征图。
- 搜索区域 $S^{t+\delta}_i$ 是 $R^t_i$ 通过一个比例因子 r (r > 1) 扩展获得的,不过扩展前后保持相同的几何中心。 如图黄色虚线框所示。
- 作者使用 Mask-RCNN 对区域提取特征 $\mathbf{f}^t_{R_i}$ 和 $\mathbf{f}^{t+\delta}_{S_i}$ 。
$v^{t+\delta}_i$ 是在 $t+\delta$ 时刻对检测到的实例 $i$ 的可见性置信度。只要实例在 $S^{t+\delta}_i$ 可见, $\mathcal{T}$ 就会产生一个高分置信度 $v^{t+\delta}_i$ ,否则 $\mathcal{T}$ 会产生一个低分的。
此公式的建模过程和很多基于 Simaese 的单目标跟踪器的思路非常相似。例如:“Fully-convolutional siamese networks for object tracking.”、“Siamrpn++” 等。因此在多目标跟踪场景中只需要多次使用上式,即可完成每个 $R^t_i \in \mathbf{R}^t$ 的预测。 SiamMOT 允许这个操作并行进行,并且只需要计算一次 backbone ,大大提高了在线跟踪的效率。
后续需要从代码中去寻找这个方法。
作者从刚开始就提出运动建模对于 Online MOT 的重要性,如果
- $\tilde{R}^{t+\delta}$ 没有匹配上正确的 $R^{t+\delta}$
- 对于 $t+\delta$ 帧上的可见行人的置信度分数 $v^{t+\delta}$ 太低
则 ${R}^{t}$ 和 $R^{t+\delta}$ 的关联会失败。所以运动建模对于 MOT 至关重要。