FastReID 是一个 SOTA 级的 ReID 方法集合工具箱(SOTA ReID Methods and Toolbox),同时 面向学术界和工业界落地 ,此外该团队还发布了在多个不同任务、多种数据集上的SOTA模型。
FastReID 中实现的四大 ReID 任务:
- 行人重识别
- 部分区域的行人重识别
- 跨域的行人重识别
- 车辆的重识别
FastReID 架构
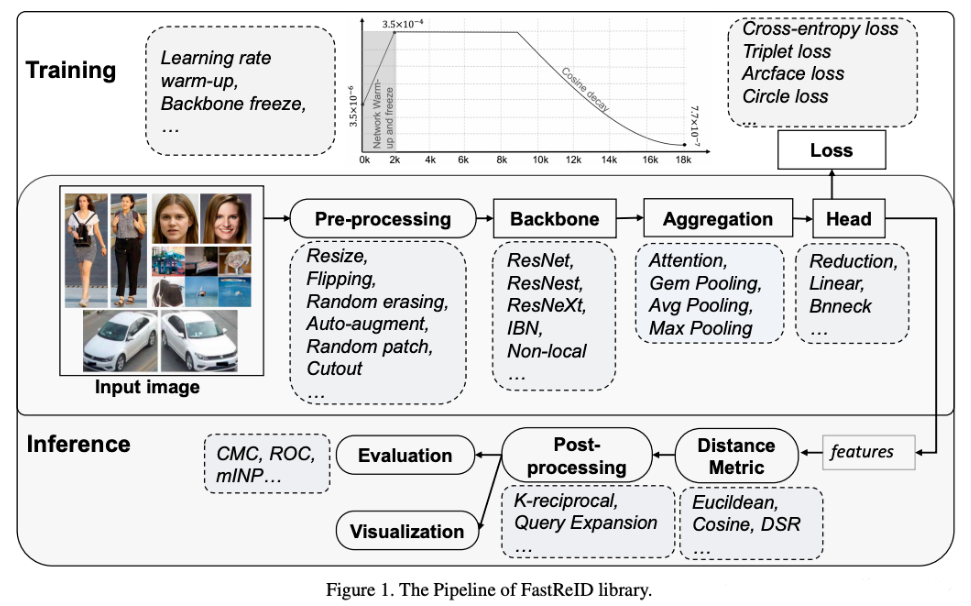
训练阶段模块包括:
- 预处理(Pre-processing)
主要是对数据进行增广,例如 Resize、Flipping、Random erasing、Auto-augment(automl 中的技巧,使用该技巧去实现有效的数据增强,提高特征的鲁棒性)、Random patch、Cutout 等;其中 Random erasing 在 reid 任务中效果显著。
数据预处理如图所示:

- Backbone
则是主干网的选择,如 ResNet、ResNest、ResNeXt等,以及可以增强 backbone 表达能力的特殊模块,如 non-local、instance batch normalization(IBN)模块等。
- 聚合模块(Aggregation)
用于将 backbone 生成的特征聚合成一个全局特征,使用的方法如 max pooling、average pooling、GeM pooling、attention pooling 等。
聚合模块中将 $\mathbf{X} \in \mathbb{R}^{W \times H \times C}$ 作为输入,向量 $\mathbf{f} \in \mathbb{R}^{1 \times 1 \times C}$ 作为聚合输出,其中 $W,H,C$ 表示宽、高以及特征图的通道。
随后使用一下聚合方法得到一个全局特征向量 $\mathbf{f}={f_1, \dots , f_c, \dots ,f_C}$
\[\mathrm{Max \ \ Pooling} : f_c = \max_{x \in \mathbf{X}_c}{x} \ \ \ \ \ (1)\] \[\mathrm{Avg \ \ Pooling} : f_c = \frac{1}{\left| X_c \right|} \sum_{x \in \mathbf{X}_c}{x} \ \ \ \ \ (2)\] \[\mathrm{Gem \ \ Pooling} : f_c = (\frac{1}{\left| X_c \right|} \sum_{x \in \mathbf{X}_c}{x^{\alpha}})^{\frac{1}{\alpha}} \ \ \ \ \ (3)\] \[\mathrm{Attention \ \ Pooling} : f_c = \frac{1}{\left| X_c * \mathbf{W}_c \right|} \sum_{x \in \mathbf{X}_c,w \in \mathbf{W}_c}{w*x} \ \ \ \ \ (4)\]其中 $\alpha$ 是控制系数, $\mathbf{W}_c$ 是 softmax 注意力权重。
- Head
Head 是处理聚合全局向量,一般生成的特征的维度比较大,需要对特征进行降维和归一化,以便于进行存储。包括 batch normalization head、Linear head、 Reduction head 三种类型的 head。
Linear head 包含决策层(decision layer)
Batch Normalization head 包含 bn layer 和决策层
Reduction head 包含 conv+bn+relu+dropout 的操作,有 reduction layer 和 decision layer
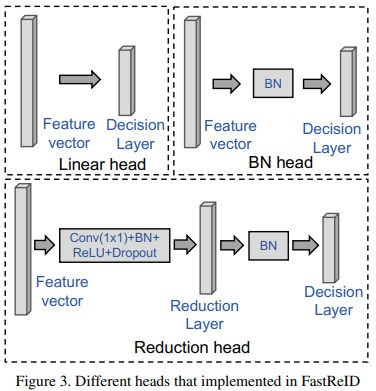
Batch Normalization 是对全局特征向量进行归一化,Reduction layer 则是对特征维度约减,最后 Decision layer 输出不同类别的概率,以区分以下模型训练的不同类别。
- 训练策略(Traning)
目前大多数网络采用的是 ImageNet 的 pre-trained 模型,一些新加的层没有进行预训练,在模型的训练初期采用 Backbone Freeze 和 Network Warm-up 的方式对模型预训练。
- 损失函数
包括常见的Cross-entropy loss,Triplet loss,Arcface loss, Circle loss。
在推理阶段,包含模块:
度量部分,除支持常见的余弦和欧式距离,还添加了局部匹配方法 deep spatial reconstruction (DSR)。
度量后处理指对检索结果的处理,包括 K-reciprocal coding 和 Query Expansion (QE) 两种重排序方法。
自认为,FastReID 就是集成了多方法的工具包,里面包含了各种训练方法用于提升精准度。然而,通过该框架也能够清除所训练出的模型量是非常大的,因此后面有用到了 Network Warm-up 去减少模型量。
后续工作会在 FastReID 中进行实验,通过该方法减少项目中 ID Switch 的问题。