Byteck:Multi-Object Tracking by Associating Every Detection Box(通过关联每个检测框进行多目标跟踪)
检测分数较低的物体,例如遮挡物体,被简单地丢弃,这带来了不可忽略的真实物体丢失和碎片轨迹。
即通过关联每个检测框而不是仅关联高分检测框来进行跟踪,对于低分数检测框,利用它们与tracklet(轨迹)的相似性来恢复真正的目标并且过滤掉背景检测信息。
30 FPS running speed on a single V100 GPU.
BYTE
保留了每个检测框,并将其分为高分检测框和低分检测框。首先将高分检测框与tracklet相关联。而有些发生遮挡、运动模糊或大小更改时,需要将这些低分检测框与不匹配的轨迹关联起来
- 输入:
- 视频序列 $\mathsf{V}$
- 目标检测器 Det
- 卡尔曼滤波器 KF
- 三个分数阈值(检测分数的阈值: $\tau_{hight}$ 、 $\tau_{low}$ 和跟踪分数阈值: $\epsilon$ )
- 输出:
- 视频的轨迹: $\mathcal{T}$ ,每个轨迹包含 bounding box 和目标的 id
流程:
对于视频中的每一帧,使用检测器预测检测框和分数,然后根据检测分数的阈值 $\tau_{hight}$ 和 $\tau_{low}$ 将检测框分为 $\mathcal{D}{high}$ 和 $\mathcal{D}{low}$ 两个部分。
然后分数高于 $\tau_{hight}$ 的检测框,放入 $\mathcal{D}{high}$ ,反之对于分数在 $\tau{hight}$ 和 $\tau_{low}$ 之间的检测框放入 $\mathcal{D}_{low}$ 中。

随后,使用卡尔曼滤波器预测每个目标的新的轨迹并放入 $\mathcal{T}$ 中。
检测框结果如图所示:

接下来就是对我们所得到的高分数和低分数的检测框进行处理:
首先,进行第一次关联:将高分数检测框 $\mathcal{D}{high}$ 与所有的轨迹 $\mathcal{T}$ (包括丢失的轨迹 $\mathcal{T}{lost}$ )。其相似性是通过高分检测框 $\mathcal{D}_{high}$ 和轨迹 $\mathcal{T}$ 中的预测框之间的 IOU 计算得到。
然后使用匈牙利算法完成基于相似度的匹配。如果检测框和轨迹框之间的 IOU 小于 0.2,则拒绝匹配。然后将未匹配的检测框放入 $\mathcal{D}{remain}$ 以及将未匹配的跟踪框放入: $\mathcal{T}{remain}$ 中。

第二次关联:将低分数检测框 $\mathcal{D}{low}$ 与第一次关联后剩余的轨迹 $\mathcal{T}{remain}$ 进行相关联。这样又可能会剩下一些未匹配的轨迹 $\mathcal{T}_{re-remain}$ 以及未匹配的低分数检测框。我们将这些剩下的未匹配的低分数检测框视为背景并删除掉。
其中,在第二次关联中使用 IOU 作为相似度很重要,因为低分数检测框存在严重的遮挡或运动模糊,外观特征不可靠,因此第二次关联中不使用外观相似度。

第二次关联完成后,这些未匹配的轨迹 $\mathcal{T}{re-remain}$ 放入 $\mathcal{T}{lost}$ ,如果这些轨迹超过 30 帧还未匹配上,则会从所有轨迹中删除,否则这些 $\mathcal{T}_{lost}$ 还会保存至 $\mathcal{T}$ 中。
最后,我们还会从第一次关联后的未匹配的高分数检测框 $\mathcal{D}{remain}$ 中初始化新的轨迹:对于每一个 $\mathcal{D}{remain}$ 中的检测框,如果该检测分数高于 $\epsilon$ 并且连续两帧都存在,则初始化一个新的轨迹。

ByteTrack
- 跟踪器:ByteTrack
- 检测器:YOLOX
- anchor-free
- decoupled heads
- strong data augmentations: Mosaic and Mixup
- effective label assignment strategy SimOTA
YOLOX介绍:
- CSPNet backbone
- PAN head
- two decoupled heads after the backbone network
- 一个用于回归,一个用于分类
- IoU-aware branch 在 predicted box 和 ground truth 之间

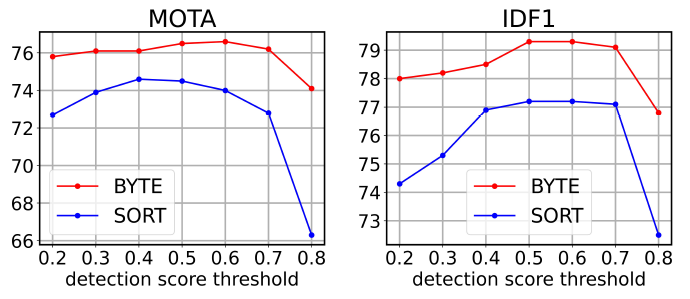
与 SORT 对比:BYTE 在 MOTA(多目标跟踪准确度。衡量单个目标跟踪准确度的一个指标)、IDF1(识别 F 值 (Identification F-Score) 是指每个行人框中行人 ID 识别的 F 值)、IDs(ID-Switch)的指标上有所提升。
\(\mathrm{MOTA} = 1 - \frac{\sum_t{(\mathrm{FN}_t+\mathrm{FP}_t+\mathrm{IDSW}_t)}}{\sum_t{\mathrm{GT}_t}}\)
- $\mathrm{FN}$ are the false nagatives (漏报),指 ground truth 中没有被检测到的数量。即整个视频漏报数量之和。
- $\mathrm{FP}$ are the false positives (误报), 指模型错误检测到错误的目标的数量,被检测到的目标不在 ground truth 中。即整个视频误报数量之和。
- $\mathrm{IDSW}$ is the number of identity switched,指一个目标的轨迹中,从 ground truth 变到了另一个目标(id值发生改变)的次数。即整个视频误配数量之和。 \(\mathrm{IDF1} = \frac{2 \cdot \mathrm{IDTP}}{2 \cdot \mathrm{IDTP} + \mathrm{IDFP} + \mathrm{IDFN}}\) IDTP、IDFP 分别代表真正 ID 数和假正 ID 数, IDFN 是假负 ID 数。
与 DeepSORT 对比:在严重遮挡的情况下, Re-ID 特征很弱,可能会导致更多的 ID-Switches ,相反,运动模型更可靠。
与 MOTDT 对比:MOTDT 集成了运动引导框(motion-guided box)作为传播结果与检测结果,将不可靠的检测结果与轨迹关联起来。
超参设置: