1.Anchor_base 和 Anchor_free
anchor-based类算法代表是 Faster R-CNN、SSD、RetinaNet、YoloV2/V3 等。
anchor-free类算法代表是 CornerNet、ExtremeNet、CenterNet、FCOS、YoloV1 等。
本质区别,就是 如何定义正负样本 。
anchor-based
目标检测一般都是采用 anchor-based 的方法,大致可以分为单阶段检测器和双阶段检测器。它们都是在一张图片上放置大量的预先定义好的 anchor-boxes,然后预测其类别,优化这些 anchor-boxes 的坐标,最终将这些优化后的 anchor-boxes 作为检测结果输出。
由于双阶段方法需要优化的 anchors 的数量是单阶段方法的好几倍,前者的准确率要高一些,而后者的计算效率要高一些。在常用的检测基准上,SOTA的方法一般都是 anchor-based 的。
anchor-free
Anchor-free 检测器以两种不同的方式来直接找到物体,无需预先定义 anchors 。
- keypoint-based 方法(基于关键点的方法):首先定位到多个预定义或自学习的关键点,然后约束物体的空间范围。
- center-based 方法(基于中心点的方法):利用中心点或中心目标区域来定义正样本,然后预测它到目标四个边的距离。
介绍一下YOLOv3的原理
yolov3 采用了作者自己设计的 darknet53 作为主干网络,darknet53 借鉴了残差网络的思想,与 resnet101 、resnet152 相比,在精度上差不多的同时,有着更快的速度,网络里使用了大量的残差跳层连接,并且抛弃了pooling池化操作,直接使用步长为2的卷积来实现下采样。在特征融合方面,为了加强小目标的检测,引入了类似与FPN的多尺度特征融合,特征图在经过上采样后与前面层的输出进行concat操作,浅层特征和深层特征的融合,使得yolov3在小目标的精度上有了很大的提升。
在推理的时候,特征图会等分成 $S \times S$ 的网格,通过设置置信度阈值对格子进行筛选,如果某个格子上存在目标,那么这个格子就负责预测该物体的置信度、坐标和类别信息。
介绍一下yolov5
v5的原理可以分为四部分:输入端、backbone、Neck、输出端;
- 输入端:针对小目标的检测,沿用了v4的
mosaic增强,当然这个也是v5作者在他复现的v3上的原创,对不同的图片进行随机缩放、裁剪、排布后进行拼接;二是自适应锚框计算,在v3、v4中,初始化锚框是通过对coco数据集的进行聚类得到,v5中将锚框的计算加入了训练的代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值; - backbone:沿用了V4的
CSPDarkNet53结构,但是在图片输入前加入了Focus切片操作,CSP结构实际上就是基于Densnet的思想,复制基础层的特征映射图,通过dense block发送到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。在v5中,提供了四种不同大小的网络结构:s、m、l、x,通过depth(深度)和width(宽度)两个参数控制。 - Neck:采用了
SPP+PAN多尺度特征融合,PAN是一种自下而上的特征金字塔结构,是在FPN的基础上进行的改进,相对于FPN有着更好的特征融合效果。 - 输出端:沿用了V3的head,使用GIOU损失进行边框回归,输出还是三个部分:置信度、边框信息、分类信息。
介绍yolov5中Focus模块的原理和作用
Focus模块,将W、H信息集中到通道空间,输入通道扩充了4倍,作用是可以使信息不丢失的情况下提高计算力。具体操作为把一张图片每隔一个像素拿到一个值,类似于邻近下采样,这样我们就拿到了4张图,4张图片互补,长的差不多,但信息没有丢失,拼接起来相当于RGB模式下变为12个通道,通道多少对计算量影响不大,但图像缩小,大大减少了计算量。
以Yolov5s的结构为例,原始640×640×3的图像输入Focus结构,采用切片操作,先变成320×320×12的特征图,再经过一次32个卷积核的卷积操作,最终变成320×320×32的特征图。
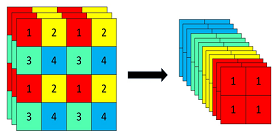
yolov4和v5均引入了CSP结构,介绍一下它的原理和作用
CSP 结构是一种思想,它和 ResNet 、 DenseNet 类似,可以看作是 DenseNet 的升级版,它将 feature map 拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行 concate 。主要解决了三个问题:1. 增强 CNN 的学习能力,能够在轻量化的同时保持着准确性;2. 降低计算成本;3. 降低内存开销。 CSPNet 改进了密集块和过渡层的信息流,优化了梯度反向传播的路径,提升了网络的学习能力,同时在处理速度和内存方面提升了不少。
对于小目标检测,你有什么好的方案或者技巧?
- 图像金字塔和多尺度滑动窗口检测(MTCNN)
- 多尺度特征融合检测(FPN、PAN、ASFF等)
- 增大训练、检测图像分辨率;
- 超分策略放大后检测;
介绍一下NMS和IOU的原理
NMS 全称是 非极大值抑制 ,顾名思义就是抑制不是极大值的元素。在目标检测任务中,通常在解析模型输出的预测框时,预测目标框会非常的多,其中有很多重复的框定位到了同一个目标,NMS的作用就是用来除去这些重复框,从而获得真正的目标框。而NMS的过程则用到了 IOU 。IOU 是一种用于衡量真实和预测之间相关度的标准,相关度越高,该值就越高。IOU的计算是两个区域重叠的部分除以两个区域的集合部分,简单的来说就是交集除以并集。
在NMS中,首先对预测框的置信度进行排序,依次取置信度最大的预测框与后面的框进行IOU比较,当IOU大于某个阈值时,可以认为两个预测框框到了同一个目标,而置信度较低的那个将会被剔除,依次进行比较,最终得到所有的预测框。
介绍一下CenterNet的原理,它与传统的目标检测有什么不同点?
CenterNet 是属于 anchor-free 系列的目标检测算法的代表作之一,与它之前的目标算法相比,速度和精度都有不小的提高,尤其是和yolov3相比,在速度相同的情况下,CenterNet精度要比yolov3高好几个点。它的结构非常的简单,而且不需要太多了后处理,连NMS都省了, 直接检测目标的中心点和大小 ,实现了真正的 anchor-free 。CenterNet 论文中用到了三个主干网络:ResNet-18 、 DLA-34 和 Hourglass-104 ,实际应用中,也可以使用 resnet-50 等网络作为 backbone;CenterNet的算法流程是:一张 512 512( $1 \times 3 \times 512 \times 512$ )的图片输入到网络中,经过backbone特征提取后得到下采样32倍后的特征图( $1 \times 2048 \times 16 \times 16$),然后再经过三层反卷积模块上采样到 128 128 的尺寸,最后分别送入三个head分支进行预测:分别预测物体的类别、长宽尺寸和中心点偏置。其中推理的核心是从headmap中提取需要的 bounding box ,通过使用$3 \times 3$的最大池化,检查当前热点的值是否比周围的8个临近点值都大,每个类别取100个这样的点,经过box后处理后再进行阈值筛选,得到最终的预测框。