Redis
说一下你再项目中的redis的应用场景?
- 5大value类型,根据我的redis课有场景的介绍
- 基本上就是缓存
- 为的的是服务无状态,延伸思考,看你的项目有哪些数据结构或对象,在单机里面需要单机锁,在多机需要分布式锁,抽出来放入redis中
- 无锁化
Set、Zset分别用于哪些场景?
Redis的数据类型
Redis的数据类型共有五种:string,list,hash,set,zset;
- String 字符串相对来说做平常,key-value,类似是hashmap的用法;
- List 队列,可以双向的存值,设计时,也可以简单用来当队列模式;
- Hash 字典,一个key 对应多个值;
- Set 无序的集合;
- Zset 有序的集合;
redis 集合(set)类型和list列表类型类似,都可以用来存储多个字符串元素的集合。但是和list不同的是set集合当中不允许重复的元素。而且set集合当中元素是没有顺序的,不存在元素下标。
redis的set类型是使用哈希表构造的,它支持集合内的增删改查,并且支持多个集合间的交集、并集、差集操作。可以利用这些集合操作,解决程序开发过程当中很多数据集合间的问题
redis 是单线程还是多线程
- 无论什么版本,工作线程就是一个
- 6.x高版本出现了IO多线程
- 使用上来说,没有变化
- [去学一下系统IO课]
- 单线程,满足redis的串行原子,只不过IO多线程后,把输入/输出放到更多的线程里去并行,好处如下:
- 执行时间缩短,更快;
- 更好的压榨系统及硬件的资源(网卡能够高效的使用)
redis存在线程安全的问题吗?为什么?
重复2中的单线程串行 redis可以保障内部串行 外界使用的时候要保障,业务上要自行保障顺序
遇到过缓存穿透吗?详细描述一下
什么是穿透: 没有这笔数据
一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去后端系统查找(比如 DB)。一些恶意的请求会故意查询不存在的 key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
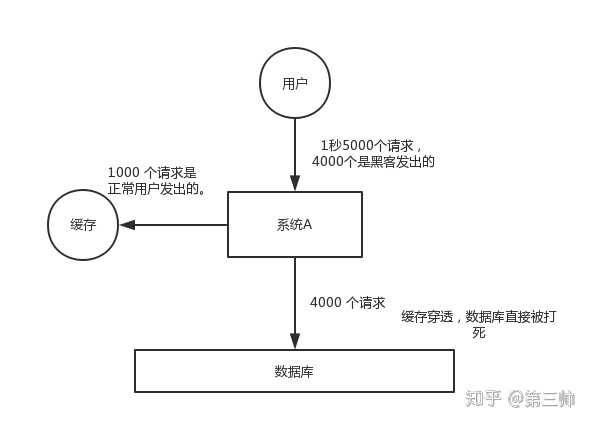
解决:
- 缓存null值。
- 缓存一个对应的key的null值,当请求下次进来的时候发现缓存对应的null就直接返回结果,不再穿透到数据库查询。
- 缺点: ==只能应对一下可预知的一定范围的请求。== 而通常都是随机一些参数进行请求,会造成缓存大量null数据,导致缓存的风险。
- 布隆过滤器
- 核心思想:不保存实际数据,而是在内存中创建一个一定长度的位图来用0和1来标记对应的数据是否存在系统。
缓存本身就是保存了一些经常使用的活跃数据,设置一定的失效时间,当一些缓存数据失效了之后,请求发现缓存没有数据就从数据库中读取再更新至缓存中。
遇到过缓存击穿吗?详细描述一下
什么是击穿: 指的是 热点key过期(没有被缓存的) 单个key 在缓存中查不到,去数据库查询,如果数据库数据量大并且是 高并发 的情况下就可能造成数据库压力过大而崩溃。
注意是 单个key发生高并发 。举个极端的例子:比如某某明星爆出一个惊天狠料,海量吃瓜群众同时访问微博去查看该八卦新闻,而微博 Redis 集群中数据在此刻正好过期了,那么无数的请求则直接打到了微博系统的物理 DB 上,DB 瞬间挂了。
解决:
- 设置热点数据(value)永远不过期
- 最可靠、最安全但占空间、内存消耗大, 并且不能保持数据更新。需要根据具体的业务逻辑来做。
- 使用互斥锁(mutex key)
- 等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
- 挡住了无效请求、重复请求
遇到过缓存雪崩吗?详细描述一下
什么是雪崩: 指的是 多个key 查询并且出现 高并发 ,缓存中失效或者查不到,然后都去DB查询,从而导致DB压力突然飙升,从而崩溃
缓存雪崩是指缓存中大批量数据到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
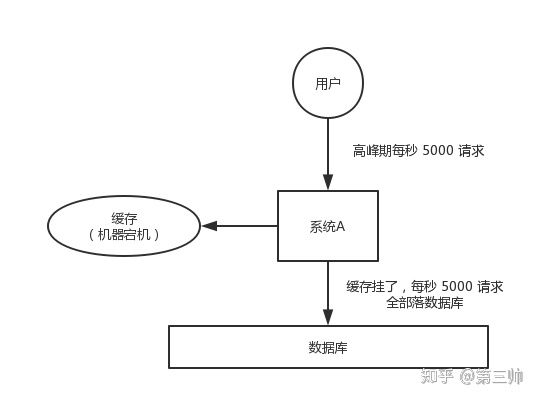
解决方案:
- Redis 失效时间加上随机数
- Redis 失效时间加上随机数,是一种比较取巧的解决方案。在一定程度上减轻了 DB 的瞬时压力,但是这种方案也在一定程度上增加了维护的成本。
- Redis 永不过期即延长热点key的过期时间或者设置永不过期
Redis是怎么删除过期key的?
缓存是如何回收的?
- 后台在轮询,分段分批的删除哪些过期的key
- 请求的时候判断已经过期了
尽量的把内存无用空间回收回来
缓存是如何淘汰的?
- 内存空间不足的情况下:
- 淘汰机制里有不允许淘汰
- LRU/LFU/random/TTL
- 全空间
- 设置过过期的key 的集合中
记录 LRU 算法
1 | |